

전화기 너머로 들려오는 소리, 혹은 복도에서 멀리 들려오는 발소리 같은 대화. 얼굴은 보이지 않아도 우리는 단번에 “아, 저건 ○○ 목소리야!” 하고 알아차립니다. 그런데 신기하지 않나요? 수많은 사람이 비슷한 말을 해도, 우리는 왜 목소리만 듣고도 누군지 구별할 수 있을까요? 그 비밀은 바로 성대 구조, 음파의 특징, 그리고 뇌의 인식 과정에 숨어 있습니다.
1. 성대의 구조 – 목소리의 ‘지문’
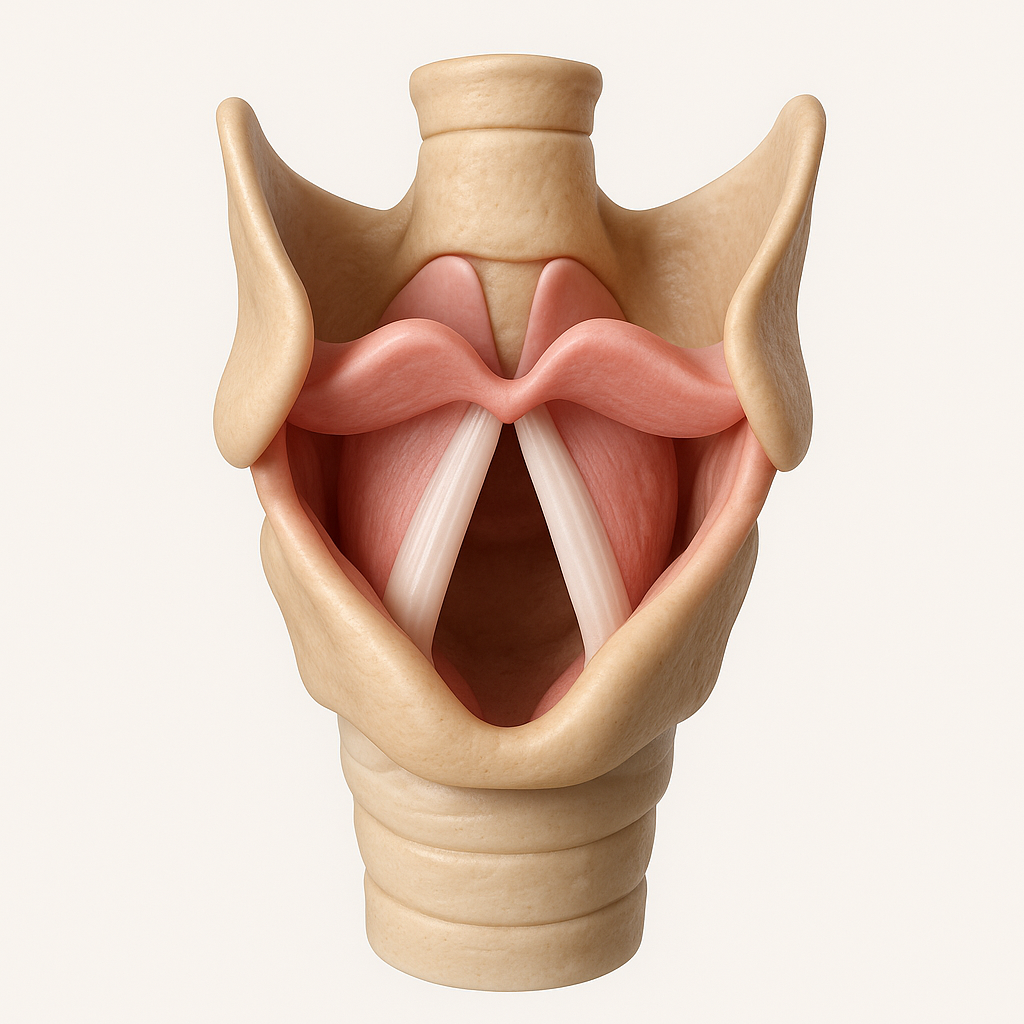
목소리를 만드는 첫 번째 요소는 성대입니다. 성대는 후두에 있는 두 개의 근육성 막으로, 우리가 숨을 내쉴 때 성대가 진동하면서 소리가 납니다. 그런데 사람마다 성대의 길이, 두께, 긴장도는 조금씩 다릅니다.
- 남성은 평균적으로 성대가 길고 두꺼워 낮고 깊은 목소리가 나고,
- 여성과 어린이는 성대가 짧고 얇아 상대적으로 높은 목소리가 납니다.
이 차이는 마치 지문처럼 고유하기 때문에, 같은 말을 해도 사람마다 완전히 다른 목소리가 되는 거죠.
👉 그래서 “목소리는 제2의 얼굴”이라는 말이 나오는 겁니다.
2. 음파의 개성 – 공명과 억양
목소리는 단순히 성대에서만 결정되지 않습니다. 소리가 성대에서 나온 뒤, 입·코·목·흉곽을 거치면서 공명(Resonance)이라는 과정을 거칩니다. 이를 ‘성도(聲道)’라고 부르는데, 사람마다 이 통로의 크기와 모양이 다르기 때문에 같은 성대 진동이라도 전혀 다른 울림을 만들어냅니다.
- 어떤 사람은 울림이 커서 묵직하게 들리고,
- 어떤 사람은 공명이 적어 맑고 가볍게 들리죠.
또한 억양, 말할 때의 습관, 호흡 방식까지 합쳐져서 한 사람만의 고유한 **음향 서명(Acoustic signature)**이 만들어집니다.
👉 그래서 우리는 단순히 음 높이뿐 아니라, 말하는 리듬과 억양만 들어도 상대방을 구분할 수 있습니다.
3. 뇌의 인식 과정 – 목소리를 ‘얼굴처럼’ 기억한다
목소리를 듣는 순간, 우리 뇌에서는 단순한 소리 인식이 아닌 정체성 파악이 동시에 이루어집니다. 청각 피질은 들어온 음파를 분석해 주파수와 리듬을 파악하고, 측두엽의 ‘음성 인식 영역’은 이를 종합해 **“누구의 목소리인지”**를 인식하죠.
흥미로운 사실은, 뇌는 목소리를 얼굴처럼 고유한 특징으로 저장한다는 겁니다. 그래서 오랜만에 듣는 친구의 목소리도 단번에 떠올릴 수 있고, 연예인의 목소리를 들으면 얼굴이 함께 연상되기도 합니다.
👉 즉, 뇌는 목소리를 단순한 소리가 아니라 사람을 식별하는 사회적 신호로 받아들이는 거예요.
4. 목소리 인식의 생활 속 활용
이러한 과학적 원리는 이미 여러 분야에 활용되고 있습니다.
- 보이스피싱 탐지: AI가 음성 패턴을 분석해 범죄 전화를 차단.
- 성문 인증(Voice ID): 은행이나 스마트폰에서 목소리로 본인 인증.
- AI 비서: 구글 어시스턴트나 시리 같은 서비스는 사용자 목소리를 구분해 맞춤 응답을 제공합니다.
👉 결국 목소리는 지문이나 홍채만큼 독특한 생체 정보로 쓰일 수 있다는 거죠.
5. 재미있는 사실 하나 더!
쌍둥이라도 목소리는 100% 같지 않습니다. 성대 구조는 비슷할 수 있어도, 말하는 습관·억양·호흡 패턴이 다르기 때문에 구별이 가능하죠. 그래서 오랜 친구나 가족은 쌍둥이의 목소리도 쉽게 구분해냅니다.
마무리
우리가 누구의 목소리인지 단번에 알아차릴 수 있는 이유는 단순히 귀가 좋아서가 아니라, 성대의 고유한 구조, 음파의 개성, 뇌의 정교한 인식 시스템이 함께 작동하기 때문입니다.
다음에 누군가의 목소리를 들을 때, 단순히 소리가 아니라 그 사람의 ‘보이지 않는 얼굴’을 듣고 있다고 생각해보세요. 일상 속 작은 과학이 훨씬 흥미롭게 다가올 겁니다. 🎙️
'雜學多識 > 알쓸신잡' 카테고리의 다른 글
| 우표에 담긴 세계사: 작은 종이가 남긴 거대한 기록 (1) | 2025.09.03 |
|---|---|
| 세계에서 금지된 음식과 그 이유 (0) | 2025.09.02 |
| 세계에서 가장 특이한 다리(Bridge)의 구조와 숨은 이야기 (2) | 2025.08.28 |
| 시간을 재는 다양한 방법: 모래시계부터 원자시계까지 (6) | 2025.08.27 |
| 지구에서 가장 오래 사는 동물은 누구일까?-500살 거북부터 ‘불멸의 해파리’까지 (5) | 2025.08.26 |



